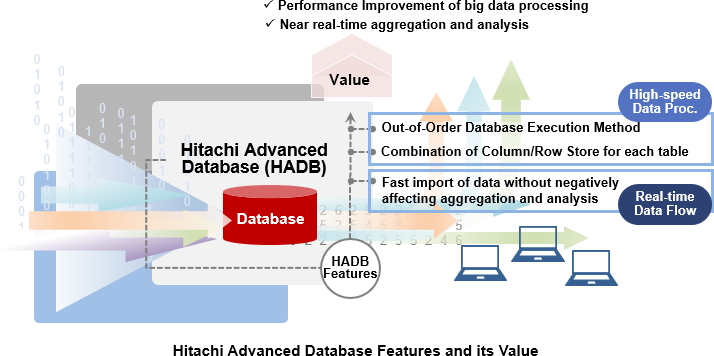
Hitachi Advanced Database is a high-speed RDBMS from Hitachi that focuses on the aggregation and analysis of massive amounts of data. Hitachi Advanced Database provides an ultra-fast search feature leveraging the out-of-order database execution method, which makes the most out of server and storage capabilities. This RDBMS also enables users to combine storage formats appropriate for the characteristics of the data and import data quickly without negatively affecting the aggregation and analysis.
With these features, Hitachi Advanced Database dramatically improves big data processing performance, periodically imports fresh data, and enables near real-time aggregation and analysis.
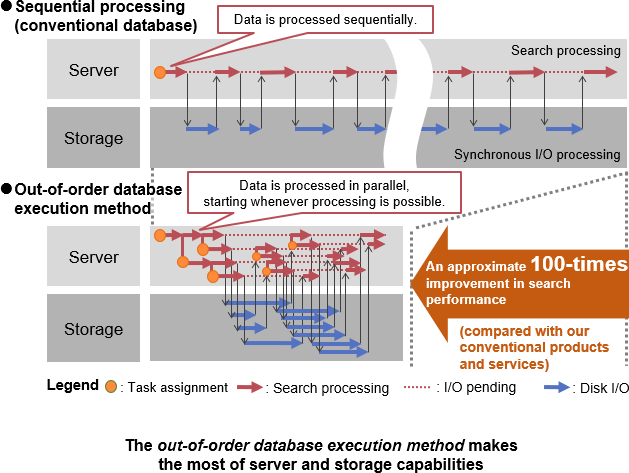
In general, when accessing massive amounts of data, many computer systems are unable to make full use of SSD-based high-speed storage or the hardware capabilities of servers with high memory capacities or multicore CPUs.
Hitachi Advanced Database resolves this issue by adopting the out-of-order database execution method to enhance data access performance.
In our system that adopt the out-of-order database execution method, requests are issued such that data processing starts whenever processing is possible and continues to process without waiting for each task to end. The principle of out-of-order execution is adopted to perform index searches, table joins, group-by aggregations, recursive queries, and other processing in parallel, resulting in increased speed.
As a result, Hitachi Advanced Database can make the most of server and storage capabilities without requiring specialized hardware and can achieve search performance approximately 100 times*1 that of our traditional products and services.
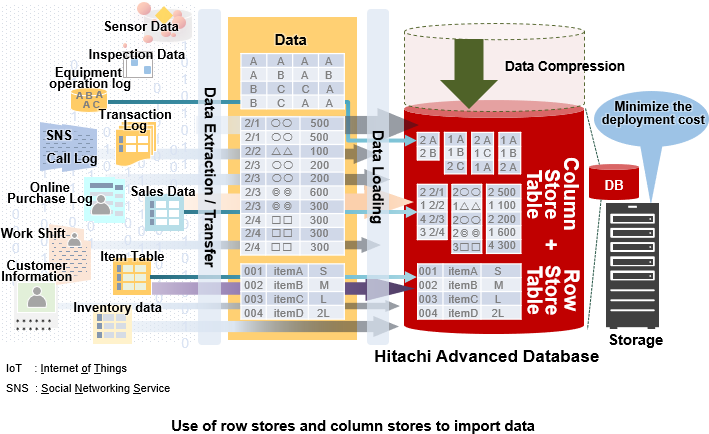
Hitachi Advanced Database users can select a storage format (row store or column store) to suit the characteristics of data. When defining tables, users can select either row store formats or column store formats for each table. Users can use both table formats at the same time for effective data access.
Row store formats are appropriate for master data and other data that is usually accessed in rows. Column store formats are appropriate for column-based data access required for aggregation and analysis. For example, column store formats are appropriate for aggregating sales data or analyzing regional trends based on average values of medical examination data.
In column store formats, data is collectively stored in columns, so the same or similar data is stored contiguously. As a result, column store formats contribute to higher compression efficiency. This can reduce the data’s size compared to storing data in the row store format. As a result, implementation costs are lowered by allowing the handling of data exceeding the storage capacity. Furthermore, when searching data, the reduction in data access volume due to data compression can speed up aggregation processing.
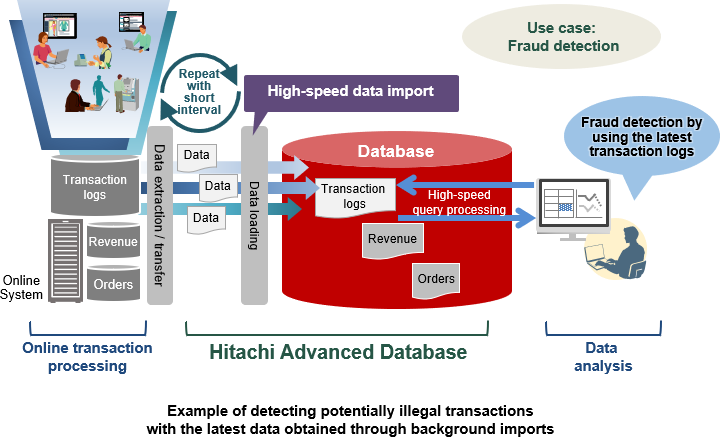
Hitachi Advanced Database can import data quickly in parallel, causing no negative impact on aggregation and analysis.
Because of this, users can import data more frequently and perform a near real-time analysis of fresh data.
As illustrated in the example below of a system that detects illegal transactions, data is quickly imported in parallel, so users can access the latest transaction logs at all times. This enables immediate detection of illegal transactions as they occur, thereby reducing fraud risk.
| Category | Item | Description |
|---|---|---|
| System specifications | Maximum system size | 1 ZB per system |
| Maximum table size | 128 EB per table | |
| DB areas | 5 to 1,024 | |
| Concurrent connections | 1 to 1,024 | |
| Database specifications | Maximum number of tables | 4,096 tables per system, 200 tables per DB area |
| Table and view columns | 1 to 4,000 | |
| Index types | B-tree index, range index, text index | |
| Maximum number of indexes | 64 per table, 8,192 per system, 400 per DB area | |
| Character encoding | UTF-8, Shift-JIS | |
| Table-data storage formats | Row store format, column store format | |
| SQL | SQL conformance levels | SQL92 and SQL99, SQL:2003 compliant (partially) |
| SQL text length | Maximum of 16,000,000 bytes | |
| Schema, table, column, or index name | Maximum of 100 bytes | |
| API | JDBC | JDBC 4.2 (Type 4 JDBC driver) |
| ODBC | ODBC 3.0, ODBC 3.5 | |
| CLI | C language API | |
| Supported platforms | OS | Red Hat® Enterprise Linux Server 7.1 or later, 64-bit x86_64 Intel 64 architecture only (Amazon EC2 and Azure Virtual Machines are also supported) |
| Data store | Block storage (HDD, SSD, Amazon EBS, Azure Managed Disks) |
|
| Object storage (Amazon S3, Azure Blob Storage) |
The table below provides examples of Hitachi Advanced Database deployments in various customer sectors.
| Sector | Purpose | Deployment details | Result |
|---|---|---|---|
| Distribution | Analyze PoS data in a timely manner, identify sales trends, and provide instructions to all stores in a timely manner. | Previously, the customer spent at least one day to create data marts for each analysis axis. In addition, they could only perform routine analysis. Currently, however, the customer can finish data analysis within one hour. As a result of the adoption of Hitachi Advanced Database, the number of data marts has been reduced, and ad-hoc analysis has been made feasible. | The time required for making a business decision (including the time required for identifying the issue and presenting case studies of similar issues in the past) was reduced. |
| Manufacturing | Implement quality control by tracing manufacturing performance (quality improvement measures such as visualization were not implemented because no data utilization platform was in place). |
Process performance data is accumulated and associated in Hitachi Advanced Database. Manufacturing information is used for visualization and retrieval. | The customer was enabled to identify the scope of impact by tracing processes from manufacturing to delivery. |
| Financial services | Detect illegal transactions as early as possible; detection of such transactions was time consuming because of batch processing at night and other factors. | Instead of carrying out batch processing at night, the customer imports transaction logs every 15 minutes and compares the logs with several hundreds of millions of past data records every hour. As a result, the customer can detect illegal transactions by quickly retrieving and using a massive amount of transaction logs while maintaining the freshness of the data. | The time required for detecting illegal transactions was reduced (from several days to several hours). |
| Financial services | Analyze potential customers by using money transfer data. | The customer can aggregate several hundreds of millions of money transfer data records from the past by running batch processing at night to analyze potential customers. | The time required for running batch processing at night was reduced. |
| Social infrastructure | Analyze the condition of new railway vehicle models. | The customer frequently imports and accumulates data, then analyzes a maximum of several billion records a day and at least 100 TB of sensor information. The customer uses the data for condition verification, trend analysis, and maintenance inspection. | The several-hundred-times increase in monitoring data due to the expansion and modernization of target equipment was accommodated. |
| Social infrastructure | Analyze sensor data on traffic. | At five-minute intervals, the customer imports at least 10 million items of sensor data per day on expressway traffic in Japan. The customer accumulates several hundred TBs of data and uses the data for fee calculation and analysis. | The customer was enabled to import and analyze a massive amount of data in near real-time. |
